
🎯 TL;DR
Nodus extrae grafos de conocimiento desde texto usando Gemini, convirtiendo notas de reuniones y artículos en redes visuales de conceptos conectados. Ves relaciones de un vistazo en lugar de buscar entre páginas de texto. Cuesta ~$0.00018 por artículo de 500 palabras.
Elige tu ruta:
- 🚀 Úsalo ahora (5 min)
- 👀 Ver resultados (2 min)
- 🧠 Cómo funciona (15 min)
- 🔧 Detalle técnico (30 min)
🌟 Por Qué Construí Esto
Hace unos cuatro meses, descubrí el video de Thu Vu sobre cómo extraer grafos de conocimiento desde texto usando GPT-4. El concepto fue transformador: ver cómo con poco código se convertían transcripciones de reuniones y contenido de podcasts, sin estructura, en redes visuales de conocimiento estructurado que hacían que la información compleja se entendiera al instante.
Piensa en los grafos de conocimiento como una forma de representar información tal como tu cerebro la organiza naturalmente, a través de conexiones y relaciones. En lugar de leer páginas de texto para entender cómo se relacionan los conceptos, ves un mapa visual donde todo está conectado.
de ver el mundo como una máquina a entenderlo como una red
Fritjof Capra ➡️
Este principio aplica perfecto a la gestión del conocimiento. Entender información no se trata de memorizar datos, sino de ver cómo se conectan.
📸 Míralo En Acción
Transforma esta oración:
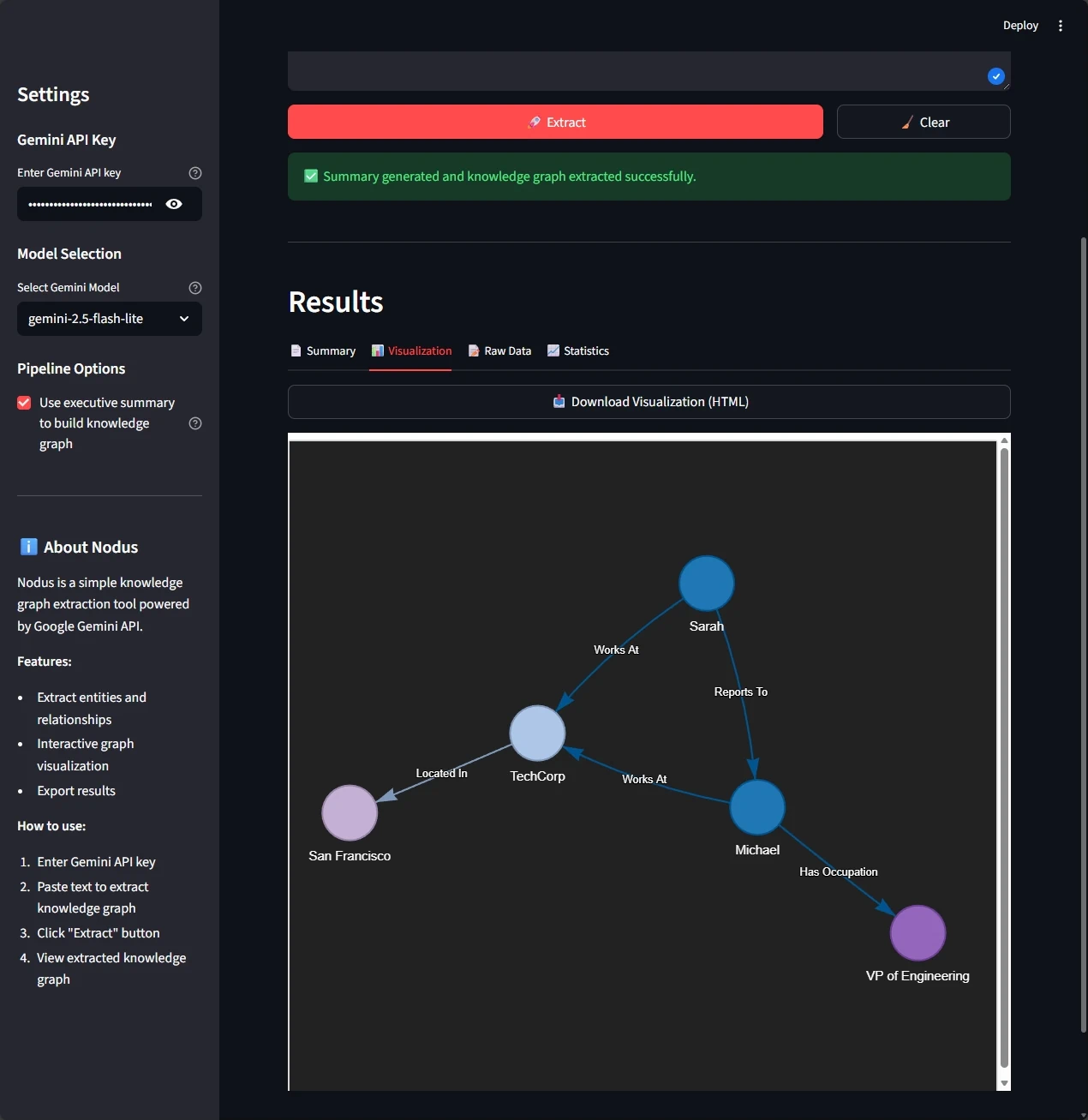
Sarah trabaja en TechCorp en San Francisco y le reporta a Michael, quien es el VP of Engineering.
En este grafo estructurado:
- Entidades: Sarah (persona), TechCorp (organización), San Francisco (ubicación), Michael (persona), VP of Engineering (ocupación)
- Relaciones: Sarah WORKS_AT TechCorp, TechCorp LOCATED_IN San Francisco, Sarah REPORTS_TO Michael, Michael HAS_ROLE VP of Engineering
💡 El Problema (En 60 Segundos)
Este es el reto fundamental: el conocimiento normalmente se crea y se guarda como lenguaje natural (documentos, transcripciones, artículos), pero es más útil cuando se estructura como un grafo.
El texto tradicional es difícil de navegar:
- 📝 Caos en notas de reuniones: buscar entre horas de transcripción para encontrar “¿Quién mencionó esa fecha límite del proyecto?”
- 🔍 Sobrecarga en investigación: leer páginas de documentación para entender cómo se conectan los conceptos
- 🏢 Conocimiento disperso: información de la empresa atrapada en wikis, docs y conversaciones, sin una vista unificada
Los datos no son información. La información, a diferencia de los datos, es útil. Aunque hay un abismo entre los datos y la información, hay un océano enorme entre la información y el conocimiento. Lo que mueve los engranajes en nuestro cerebro no es la información, sino las ideas, las invenciones y la inspiración
Clifford Stoll ➡️
✨ La Solución
Esto fue lo que hizo tan convincente ese descubrimiento inicial: los LLM modernos cambiaron la ecuación. Pueden leer texto y extraer información estructurada con una precisión sorprendente, entendiendo contexto, resolviendo ambigüedades e identificando relaciones que los sistemas tradicionales de NLP no detectarían.
Los LLM no solo generan texto. Pueden imponer estructura al caos, convirtiendo grandes corpus de texto en redes de conocimiento navegables.
Lo que hace Nodus:
- ✅ Extrae entidades y relaciones de cualquier texto
- ✅ Crea grafos de conocimiento visuales e interactivos
- ✅ Soporta múltiples formatos de exportación (HTML, JSON, TXT)
- ✅ Cuesta centavos por extracción (~$0.00018 por artículo)
- ✅ No requiere etiquetado manual ni pipelines complejos de NLP
En lugar de construir sistemas de extracción complicados, escribes código directo que aprovecha la capacidad de salida estructurada de Gemini. La extracción de conocimiento sofisticada se volvió accesible con una implementación relativamente simple.
🚀 Inicio Rápido
Obtén el código fuente
# Clone repository without downloading all files
git clone --depth 1 --filter=blob:none --sparse git@github.com:jebucaro/blog-code.git
# Navigate to repository
cd blog-code
# Download only the folder you need
git sparse-checkout set python/Nodus
# Navigate to the Nodus project directory
cd python/Nodus
Configura el proyecto
# Copy the example environment file
cp .env.example .env
# Edit .env and replace the empty GEMINI_API_KEY value with your actual key
# On Windows: notepad .env (or your preferred editor)
# On Mac/Linux: nano .env (or your preferred editor)
# Install dependencies
uv sync
Lanza la aplicación
Opción 1: usando uv
uv run streamlit run src/nodus/main.py
Opción 2: usando Docker
# 1. Ensure Docker Desktop is running, then build the image
docker build -t nodus:latest .
# 2. Run with environment variable
docker run -p 8501:8501 -e GEMINI_API_KEY=your_key_here nodus:latest
# 3. Or use .env file
docker run -p 8501:8501 --env-file .env nodus:latest
# 4. Access the app at http://localhost:8501
📊 Resultados
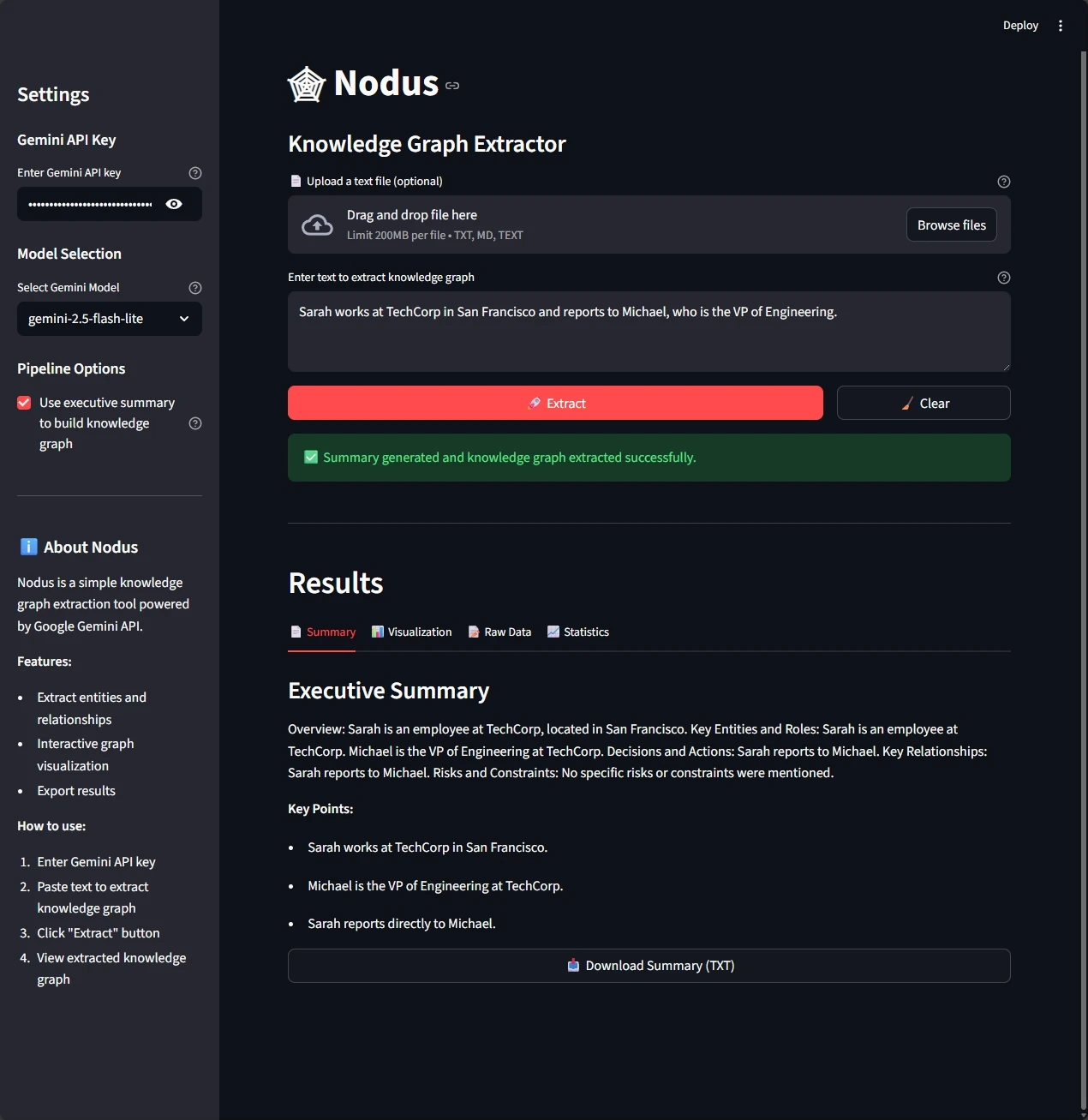
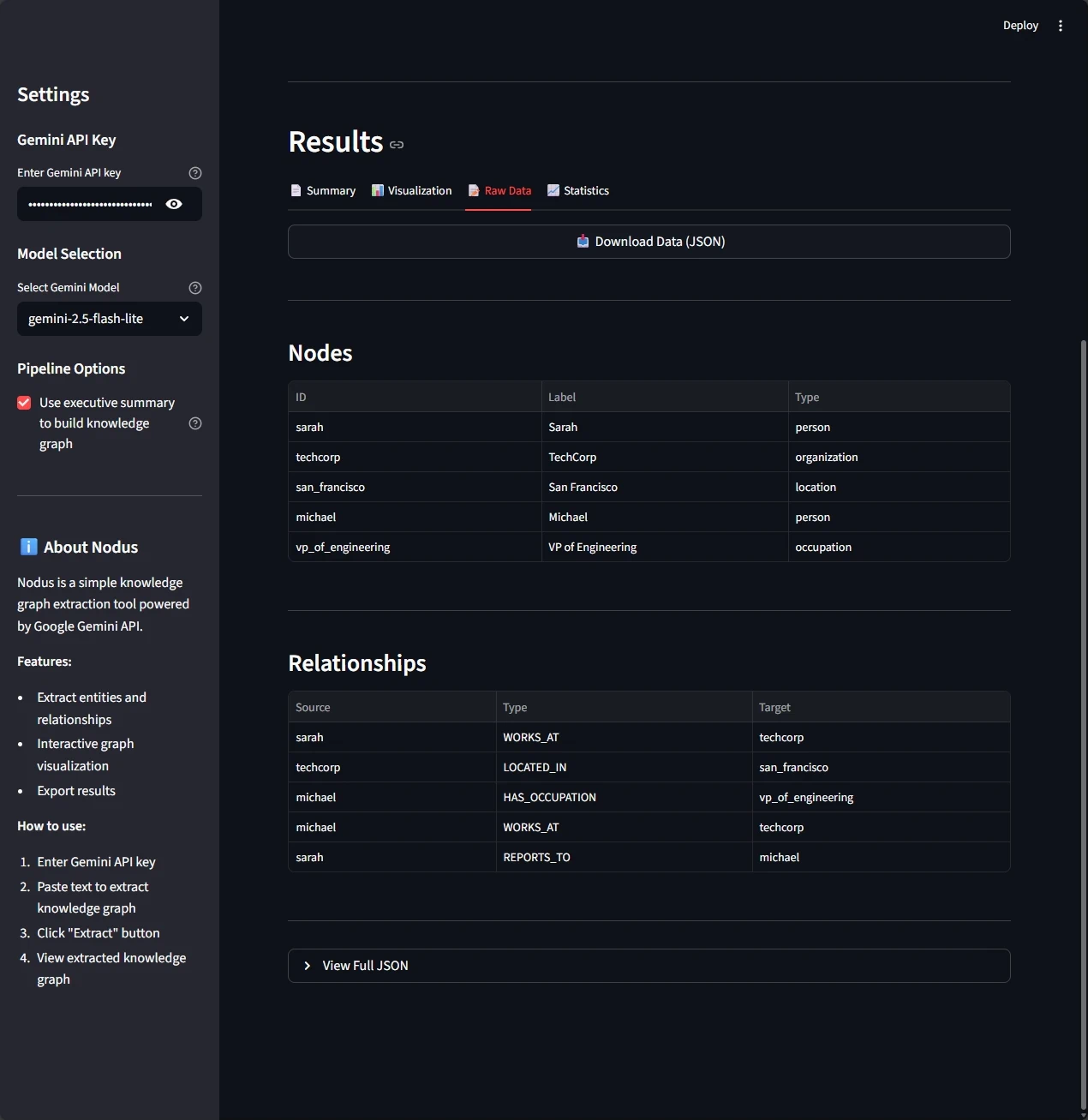
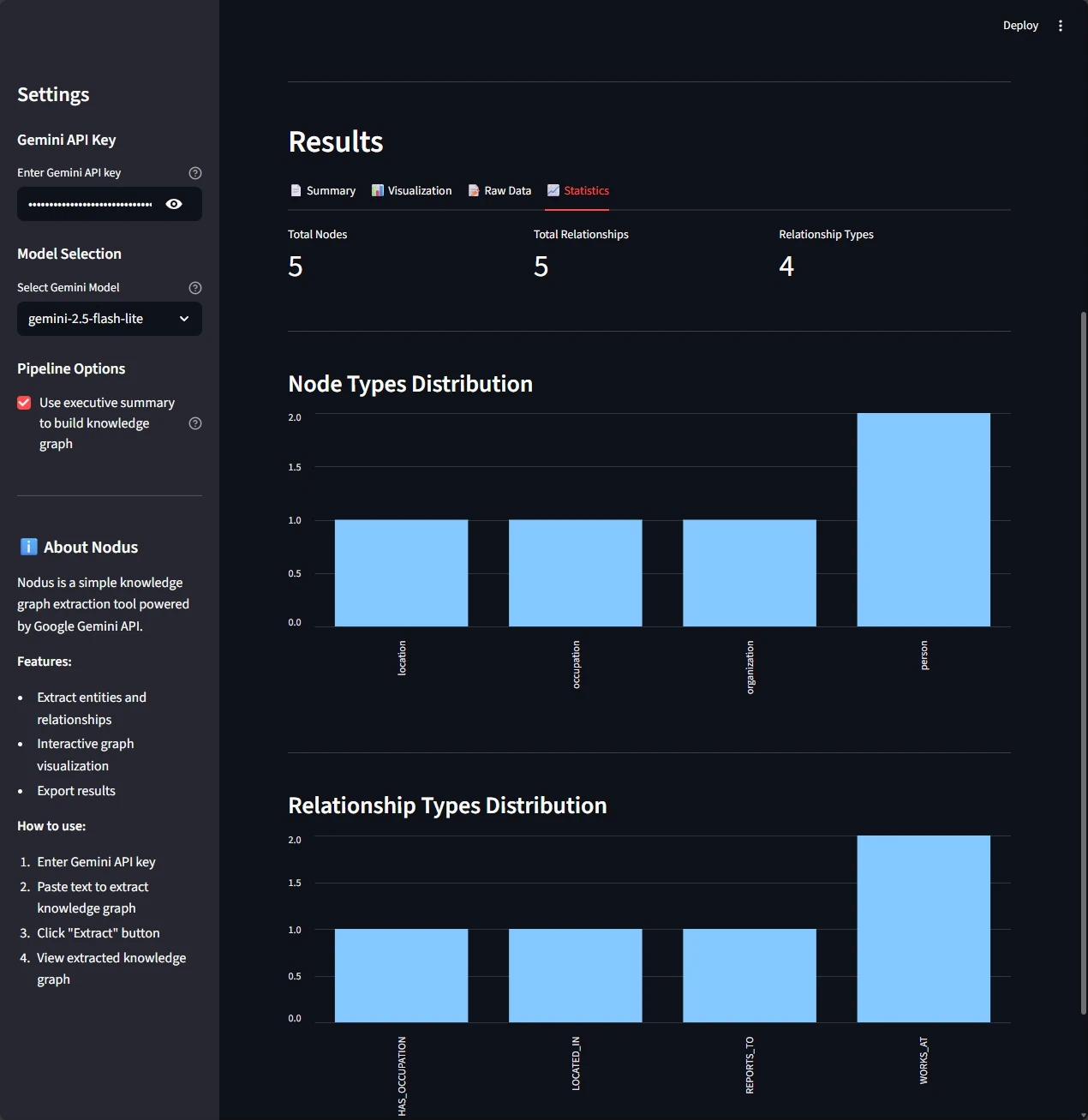
La interfaz te da cuatro perspectivas del conocimiento extraído:
Lo Que Obtienes
Vista de resultados en cuatro pestañas:
- Resumen: briefing ejecutivo estructurado con los insights clave
- Visualización: exploración interactiva del grafo con layout basado en física
- Datos sin procesar: inspección del JSON de nodos y relaciones
- Estadísticas: métricas del grafo (cantidad de nodos, tipos de relaciones, etc.)
Opciones de exportación:
- HTML (grafo interactivo)
- JSON (datos estructurados)
- TXT (resumen)
🏗️ Cómo Funciona (Arquitectura)
Diseñé esta implementación para priorizar claridad sobre abstracción. Cada capa es intencionalmente simple, lo que facilita entender, modificar y extender. Piensa en esto como una base de aprendizaje, no como un framework listo para producción.
El sistema usa cuatro capas enfocadas:
1. 📝 Capa de extracción: donde la estructura se encuentra con el lenguaje
Los LLM modernos con soporte de salida estructurada pueden aceptar definiciones de esquema directamente, eliminando el parseo manual de JSON. Esta es una de las funciones más potentes que hace que la extracción de grafos de conocimiento sea tan accesible hoy.
El extractor implementa un proceso de extracción en dos fases:
Fase 1: generación de resumen ejecutivo Primero, el sistema genera un resumen ejecutivo estructurado con cinco secciones clave (Overview, Key Points, Entities, Relationships, Conclusions). Este resumen opcional da contexto de alto nivel.
Fase 2: extracción del grafo de conocimiento Luego el sistema extrae entidades y relaciones, ya sea desde el resumen ejecutivo (para grafos más enfocados y de alto nivel) o directamente desde el texto original (para más detalle).
class GeminiExtractor:
def extract_with_summary(
self,
text: str,
use_summary_for_kg: bool = True
) -> ExtractionResult:
# Generate summary first
summary = self.summarize(text)
# Extract KG from summary or original text
source = summary.content if use_summary_for_kg else text
kg = self.extract(source)
return ExtractionResult(summary=summary, knowledge_graph=kg)
Requisitos clave para extracción consistente:
- Los identificadores de nodos deben ser semánticos y en minúsculas con guiones bajos (
sarahen lugar deperson_1) - Los tipos de relación deben ir en MAYÚSCULAS con guiones bajos (
WORKS_ATy noworks_at) - Las reglas de correferencia deben ser explícitas (asegurar que “Michael” y “he” apunten a la misma entidad)
Estas restricciones mejoran mucho la depuración y la calidad del grafo. IDs numéricos genéricos hacen que resolver problemas de extracción sea difícil.
2. 🗂️ Modelos de datos: definiendo la estructura
Modelos de datos claros establecen el contrato entre el LLM y tu aplicación. Uso modelos de Pydantic para definir exactamente qué estructura espero de Gemini:
class Node(BaseModel):
id: str # Semantic identifier (lowercase with underscores)
label: str # Human-readable name (auto-generated from id if not provided)
type: str # Entity category (e.g., person, organization)
class Relationship(BaseModel):
id: str # Relationship identifier
type: str # Relationship type (UPPERCASE with underscores)
source_node_id: str
target_node_id: str
class KnowledgeGraph(BaseModel):
nodes: list[Node]
relationships: list[Relationship]
class ExecutiveSummary(BaseModel):
overview: str
key_points: list[str]
entities: list[str]
relationships: list[str]
conclusions: str
class ExtractionResult(BaseModel):
summary: ExecutiveSummary
knowledge_graph: KnowledgeGraph
Deduplicación semántica automática: el modelo KnowledgeGraph incluye deduplicación integrada que elimina relaciones redundantes de dos maneras:
- Por ID de relación (duplicados exactos)
- Por tripleta semántica:
(source_node_id, type, target_node_id)(relaciones funcionalmente equivalentes)
Esto cubre el caso común en el que los LLM generan la misma relación varias veces con IDs distintos, dejando grafos limpios y eficientes.
3. 🎨 Capa de visualización: hacer explorables los grafos
Los datos de grafo sin procesar son útiles, pero la visualización es donde ocurre la magia. De pronto ves patrones que eran invisibles en el texto:
Consistencia por codificación de colores: Usar asignación determinística de colores (hashear los tipos de nodo a una paleta) asegura que los tipos de entidad mantengan una representación visual consistente entre grafos. Esa consistencia ayuda a que las personas formen modelos mentales más rápido.
Simulación física interactiva: Algoritmos de layout como ForceAtlas2 crean visualizaciones “naturales” donde los nodos conectados se agrupan y los nodos aislados se separan. Esa organización espacial suele revelar patrones que no se ven en el JSON.
Dos modos de renderizado: Soportar tanto generación de strings HTML como salida a archivo permite integrar de forma flexible, ya sea incrustándolo en una app web o generando visualizaciones standalone.
4. 💻 Capa de interfaz: optimizar el flujo
Un flujo claro reduce fricción:
- Configuración: credenciales de API y selección de modelo
- Entrada: texto directo o carga de archivo (.txt, .md)
- Opciones del pipeline: construir el grafo desde el resumen ejecutivo o desde el texto original
- Resultados en cuatro vistas (Resumen, Visualización, Datos sin procesar, Estadísticas)
- Exportación: descargar resultados en HTML, JSON o TXT
💰 Consideraciones de costo
Una de las mejores partes de este enfoque es lo accesible que es. Te desgloso la economía:
Precios de Gemini 2.5 Flash Lite (tier de pago):
- Input: $0.10 por 1M tokens
- Output: $0.40 por 1M tokens
Ejemplo práctico: Extracción de un artículo de 500 palabras:
- ~600 tokens de entrada
- ~300 tokens de salida
- Costo de entrada: (600 / 1,000,000) × $0.10 = $0.00006
- Costo de salida: (300 / 1,000,000) × $0.40 = $0.00012
- Costo total: ~$0.00018 por extracción
Esta estructura de costos hace viable la extracción de grafos de conocimiento para aplicaciones de alto volumen y escenarios de procesamiento en tiempo real.
Nota: Gemini 2.5 Flash Lite también incluye un free tier generoso sin costo, tanto para tokens de entrada como de salida, lo que lo hace perfecto para pruebas y uso a pequeña escala.
🎯 Aplicaciones en el mundo real
Dónde lo puedes usar hoy:
📝 Notas y transcripciones de reuniones: en vez de buscar entre horas de notas para recordar “¿Quién mencionó esa fecha límite del proyecto?”, puedes consultar el grafo: “Muéstrame todas las fechas límite mencionadas por Sarah en reuniones de Q1”. Las relaciones ya están extraídas y estructuradas.
📚 Investigación y aprendizaje: al ver contenido educativo o leer documentación técnica, los grafos de conocimiento construyen un mapa de conceptos automáticamente. Puedes ver cómo se conectan las ideas, cuáles conceptos son centrales y qué podría faltarte.
🏢 Conocimiento organizacional: las empresas tienen información dispersa en documentos, wikis y conversaciones. Los grafos de conocimiento lo unifican extrayendo entidades y relaciones sin importar dónde aparezcan, creando un mapa vivo del conocimiento organizacional.
Lo que puedes construir a partir de aquí:
- Conectar a bases de datos de documentos para extracción automática
- Construir interfaces de consulta para explorar tus grafos de forma conversacional
- Implementar merge de grafos para combinar conocimiento de múltiples fuentes
- Agregar seguimiento temporal para ver cómo evoluciona el conocimiento
🔗 Explora el código
La implementación completa está disponible en GitHub ➡️ . Mantuve el código intencionalmente minimal y bien documentado para que puedas entender cada pieza y adaptarla a tus necesidades.
Empieza con estos archivos:
models.py- Modelos de datos Pydantic con validación y deduplicación automáticaextractor.py- Lógica de extracción en dos fases e ingeniería de promptsvisualizer.py- Renderizado del grafo con PyVis y algoritmos de layoutapp.py- Interfaz Streamlit con manejo de session statesettings.py- Configuración de entorno y selección de modeloerrors.py- Jerarquía de excepciones personalizada para mensajes amigables
🎓 Aprendizajes del enfoque de Thu Vu
La implementación de Thu Vu demuestra extracción de grafos de conocimiento usando GPT-4 y LLMGraphTransformer de LangChain. El video da un contexto valioso para entender cómo las abstracciones de alto nivel simplifican el proceso:
Ver esta implementación en acción muestra tanto el poder de las capas de abstracción como las preguntas que dejan abiertas. Aunque el código es conciso y efectivo, entender lo que pasa debajo se vuelve importante cuando necesitas:
- Depurar resultados de extracción inesperados
- Optimizar prompts para dominios específicos
- Adaptar el sistema a distintos proveedores de LLM
- Controlar costos a escala
Por qué lo construí desde cero
Aunque herramientas como LLMGraphTransformer hacen este proceso accesible, yo quería entender los mecanismos de fondo. Trabajar directo con las APIs da una visión más profunda de cómo funciona la extracción estructurada.
Revela los patrones centrales: Cuando quitas soporte multi-proveedor y el overhead del framework, la lógica fundamental se vuelve clara. Ves exactamente cómo la ingeniería de prompts impulsa la calidad de entidades y relaciones extraídas.
Habilita control preciso: Acceso directo a la API te permite afinar cada aspecto del proceso. Puedes iterar en el diseño del prompt, ajustar reglas de validación y optimizar para tu dominio sin navegar capas de abstracción.
Construye conocimiento transferible: Entender salida estructurada a nivel de API te prepara para trabajar con cualquier proveedor. Los principios se mantienen, aunque las herramientas y frameworks evolucionen.
Este artículo explora construir un sistema similar desde cero, enfocándose en las capacidades de salida estructurada de Gemini. El objetivo no es reemplazar enfoques basados en frameworks, sino entender los mecanismos fundamentales que hacen que la extracción de grafos de conocimiento funcione.
💬 ¿Qué vas a extraer?
Los grafos de conocimiento transforman cómo interactúas con la información. Ya sea que estés gestionando investigación, organizando notas de reuniones o construyendo aplicaciones con IA, la extracción de conocimiento estructurado abre nuevas posibilidades.
Me da curiosidad: ¿cuál es el primer texto que vas a convertir en un grafo de conocimiento? Comparte tu caso de uso o tus preguntas en LinkedIn. Me encantaría ver lo que construyes con esto.

